モンキーPython (Python3対応): 第2回 お絵かきプログラムを作ってみる 前編
 この文書は、Linux magazine 2005年1月号〜3月号に掲載された連載の草稿を、(株)アスキーLinux magazine編集部の許可を得て公開するものです。
この文書は、Linux magazine 2005年1月号〜3月号に掲載された連載の草稿を、(株)アスキーLinux magazine編集部の許可を得て公開するものです。
校正前の原稿なので読みづらいところもあるかと思います。不明な点などありましたらコメントをお送りください。
今回の目次:
- 前回のおさらい
- 基本的なオブジェクト
- 整数
- 文字列
- バイト列
- タプルとリスト
@ 前回のおさらい
簡単に前回のおさらいをしておきましょう。
- コンピュータに何かさせるには、そのための命令を書き連ねたソースコードを作る. ソースコードはいわば指示書.
- Python のソースコードに書く命令は、文を単位として解釈、実行される。
- 命令には、関数呼び出し、オブジェクトのメソッド呼び出し、print文、変数への代入などがある。
- オブジェクトは、内部に構造 (内部状態) を持ち、その操作のためのメソッドを持つ。
- オブジェクトのメソッドはクラスで定義される。オブジェクトは、クラスから生成する。クラスは, いわばオブジェクトのひな形.
特に、どのような関数があってどう呼び出すのか、どのようなクラスがあり、そのクラスでどのようなメソッドが定義されているのか、を覚えていくことが重要です。今回は、まずは、いろいろなオブジェクト (クラス) の使い方を見ていきましょう。
@ 基本的なオブジェクト
最も基本的で、多用するオブジェクトは、数値と文字列です。また、データを格納するためのオブジェクトでよく使うものに、タプル (tuple), リストがあります。
■数値
Pythonでは、数値は整数、実数、複素数に分けられます。それぞれクラス名は次の表のとおりです。
| 種類 | クラス名 |
|---|---|
| 整数 | int
|
| 実数 | float
|
| 複素数 | complex
|
(注) Python2 には, 短い整数を表す int と長整数型の long があったが、Python3 では int しかない。Python3 の int は、長い整数も表せる。
小数点以下の値が起こりうる場合は, float を使います。float は, コンピュータ内部の都合ですが, 計算誤差が発生する場合があるので、小数点以下が不要なときは整数を使います。
次のスクリプトは、数値の四則演算を行います。
02-01.py
- # -*- coding:utf-8 -*-
- print( 2 + 3 * 4 ) #=> 14
- print( (2 + 3) * 4 ) #=> 20
- print( 7 / 3 ) #=> 2.3333333333333335
- print( 7 // 3 ) #=> 2
- print( 7.0 / 3 ) #=> 2.3333333333333335
- print( 2 ** 3 ) #=> 8
普通の計算順序どおりに、掛け算 (*)・割り算 (/または//)は足し算・引き算より先に行われます。括弧で囲めば括弧の内側のほうが先に計算されます。「x ** y」は、xのy乗を表します。
(2012.9更新.) 割り算 "/" は、Python3で挙動が変更されました。"/" は, 整数同士の割り算であっても, コンピュータで表現可能な近似値を計算します。また, "//" は余りが切り捨てられます。(正確には答がマイナス無限大の方向へ丸められます。)
7 / 3では、最後の桁に計算誤差が現れていることに注意してください。
このほか、プログラミングでは 16進数の数字もよく使います。Python では, 16進数の数字は頭に '0x' を付けます。例えば、255 は16進数では 0xff になります。
■文字列
文字の連なりを文字列といいます。コンピュータにさせる仕事では、数値か文字列を扱うことが多く、非常に重要です。
Pythonでは、文字列は「"」(ダブルクォーテーション) または「'」(シングルクォーテーション) で囲んで表します。どちらも同じ意味です。文字列のクラスはstrです。
文字列同士は「+」で連結することができます (書き方は x + y)。数値であっても str() 関数で文字列に変換すれば連結できます。
次の例は, 文字列を操作します。
02-02.py のそれぞれのメソッド (いずれもstrクラスのメソッド) の働きは次のとおりです。
- count(文字列)
- 対象となる文字列オブジェクトの中に、引数の文字列がいくつあるか数えます。
- lower()
- 対象文字列中の英大文字を小文字にした新しい文字列オブジェクトを生成します(対象オブジェクトは変更しない)。
- find(文字列)
- 対象文字列から引数の文字列を検索し、最初に発見した位置を返します。文字列の位置は、0から数えます。2文字目なら1です。
文字列オブジェクト[s:t]- 先頭から数えて位置sから位置 (t - 1) までの文字で新しい文字列オブジェクトを作ります。
細かい話をすると、Python の「文字」は、Unicodeコードポイント (符号位置) というものです。一文字一文字, 文字の図形を持っているわけではなく、それぞれの文字に対応する番号だけで, 文字列を表します。
Unicodeは, ほとんどの文字を 0から 0x10FFFF までの番号一つで表現します。例えば「あ」は0x3042,「㈱」は0x3231など。昔の古いプログラミング言語では、16bit (0〜0xFFFF) を超える場合には特別な操作が必要でしたが、Python では気にする必要がありません。
ただ、コンピュータ上の文字というのはとても複雑で、ほんとうは1文字でも, 複数のUnicodeコードポイントの組み合わせになることがあります。下の画像のSource 列, NFD 列, NFC列の文字は同じですが、コンピュータ内での表現方法が違います。Python 文字列としては 2文字になったり3文字になったりします。
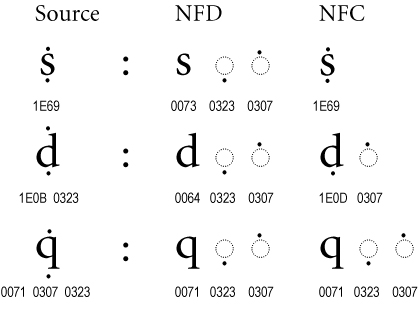
出典: http://unicode.org/reports/tr15/
■バイト列
Python では、ファイルやネットワークなど、外部とのデータのやりとりにバイト列を使います。テキスト(文字列)データも、外部とやりとりするときには, バイト列に変換します。
次の例は、文字列をバイト列に変換します。encode() の戻り値の型は bytes クラスです。
02-03.py
文字は7文字ですが、UTF-16 という形式でバイト列に変換すると22バイトになります。
 文字コードあれこれ
文字コードあれこれ
外部とのやりとりは、お互いに合意した文字コードに変換したバイト列でおこないます。ある文字をどのようなバイト(数値)の列にするかの規則が文字コードです。
文字コードは、歴史的な事情により、シフトJIS、EUC-JP、UTF-8などいくつもあります。第1回で、ソースコードの文字コードはUTF-8にするように書きました。UTF-8では、半角の英数記号文字は1文字1バイトですが、全角ひらがな・カタカナ・記号・漢字は、1文字3バイト(一部2バイト)になります。
| 日 | 本 | 語 | t | e | x | t | ☆ | β |
| e6 97 a5 | e6 9c ac | e8 aa 9e | 74 | 65 | 78 | 74 | e2 98 86 | ce b2 |
同じ文字列をEUC-JPで保存すると、次のようになります。EUC-JPでは、全角文字は1文字2バイトになります。
| 日 | 本 | 語 | t | e | x | t | ☆ | β |
| c6 fc | cb dc | b8 ec | 74 | 65 | 78 | 74 | a1 f9 | a6 c2 |
(Python2の文字列)
Python2では、文字列が2種類ありました。strクラスとunicodeクラスです。このうちunicodeクラスのほうが Python3のstrクラスになり, unicodeという名前のクラスはなくなりました。数値で, longがPython3のintになったのと同じやり方ですね。
Python2 では, 文字列をUnicodeモードにするには、スクリプト中で文字列を書くときに「"」あるいは「'」の前に「u」を付けます。unicodeクラスのメソッドは、strクラスと同じものが使えます。
リスト2で、通常モード (ASCIIモード) とUnicodeモードで文字列の扱いがどう変わるか見てみます。
Python2 の非Unicode文字列は、全角文字もバイト列にして格納されるため、find()の戻り値が文字単位になっていませんでした。Unicodeモードでは、find() の戻り値が文字単位になっていることが分かります。lower()で全角文字も小文字になるようになります。
■タプルとリスト
数値や文字列だけでは複雑なデータを表すことはできません。そこで、複数のデータを格納できるオブジェクトを導入しましょう。
Pythonでは、タプル (tupleクラス)、リスト (listクラス)などを用います。
タプルとリストはいずれも要素を一列にして格納します。タプルはいったん生成すると、要素の追加、削除はできません。一方, リストは後から追加も削除もできます。この違い以外は、タプルとリストは同じように使えます。
02-04.py は、タプルとリストを生成し、list#append() メソッドでリストに後ろ(右)から要素を追加します。文字列と同様に、オブジェクト[n]あるいはオブジェクト[lower:upper]で、要素を参照したり、一部分からなる新しいタプル、リストを作ることができます。
Note.
メソッドはオブジェクトのクラスが違っても同じ名前を付けられる(たとえ違う内容であっても)ので、以下では必要に応じて、
クラス名#メソッド名と書いて、どのクラスのメソッドなのかを明確にします。スクリプト上では、
対象オブジェクト.メソッド名(引数, ...)と書くことに注意してください。
タプルもリストも、要素それぞれの型が違っていても構いません。要素として, リストのような構造を持つオブジェクトも, 問題なく追加できます。
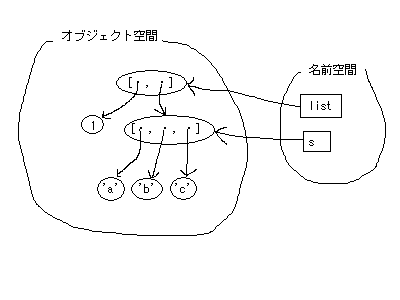
格納すると言っても、オブジェクトの内部に要素が埋め込まれる訳ではありません。外から見ると格納されているように見えますが、内部ではオブジェクトへのリンクが張られています。02-04.py で、変数sが指すリストに要素を追加すると、変数listのリストが変更されたように見えます。
オブジェクトは、図2のようにオブジェクト空間に浮かんでいます。listの2番目の要素と変数sは同じオブジェクトを指しています。